Plywood
Plywood is a JavaScript library that simplifies building interactive visualizations and applications for large data sets. Plywood acts as a middle-layer between data visualizations and data stores.
Plywood is architected around the principles of nested Split-Apply-Combine, a powerful divide-and-conquer algorithm that can be used to construct all types of data visualizations. Plywood comes with its own expression language where a single Plywood expression can translate to multiple database queries, and where results are returned in a nested data structure so they can be easily consumed by visualization libraries such as D3.js.
You can use Plywood in the browser and/or in node.js to easily create your own visualizations and applications. For an example application built using Plywood, please see Pivot.
Plywood also acts as a very advanced query planner for Druid, and Plywood will determine the most optimal way to execute Druid queries.
Should you use Plywood?
Here are some possible usage scenarios for Plywood:
You are building a web-based, data-driven application, node.js backend
Plywood primitives can serve as the 'models' for the web application. The frontend can send JSON serialized Plywood queries to the backend. The backend uses Plywood to translate Plywood queries to database queries as well as doing permission management and access control by utilizing Plywood heleprs.
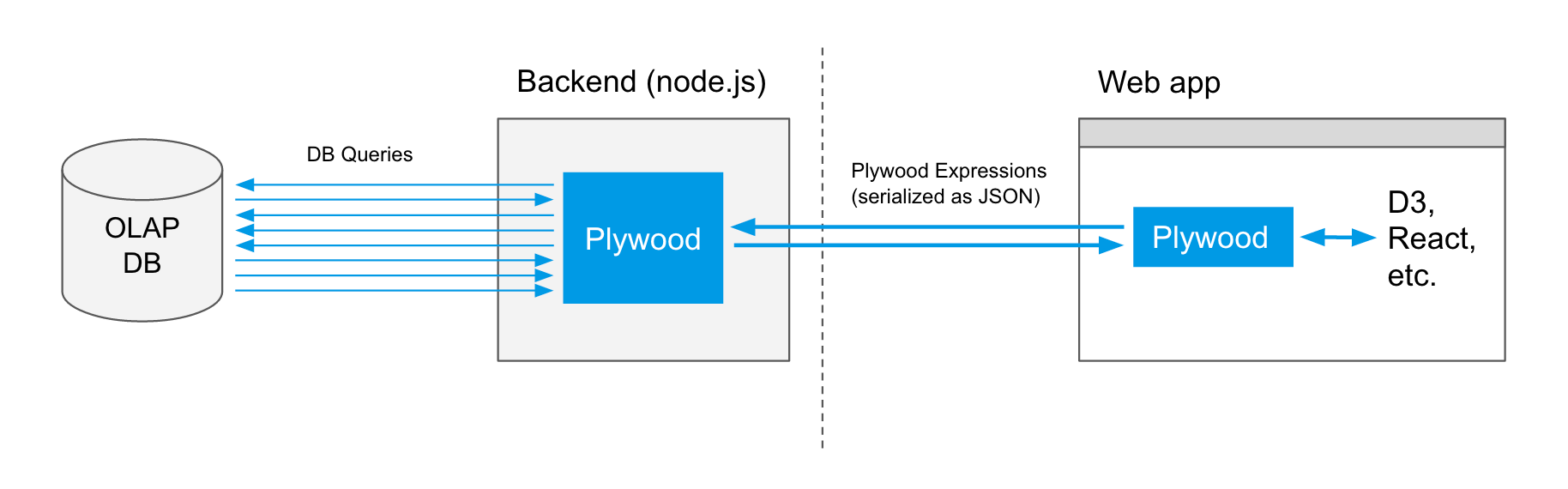
Pivot is an example of a Project that uses Plywood in this way.
You are building a web-based, data-driven application, backend not node.js
Plywood can run entirely from the browser as long as there is a way for it to issue queries from the browser.
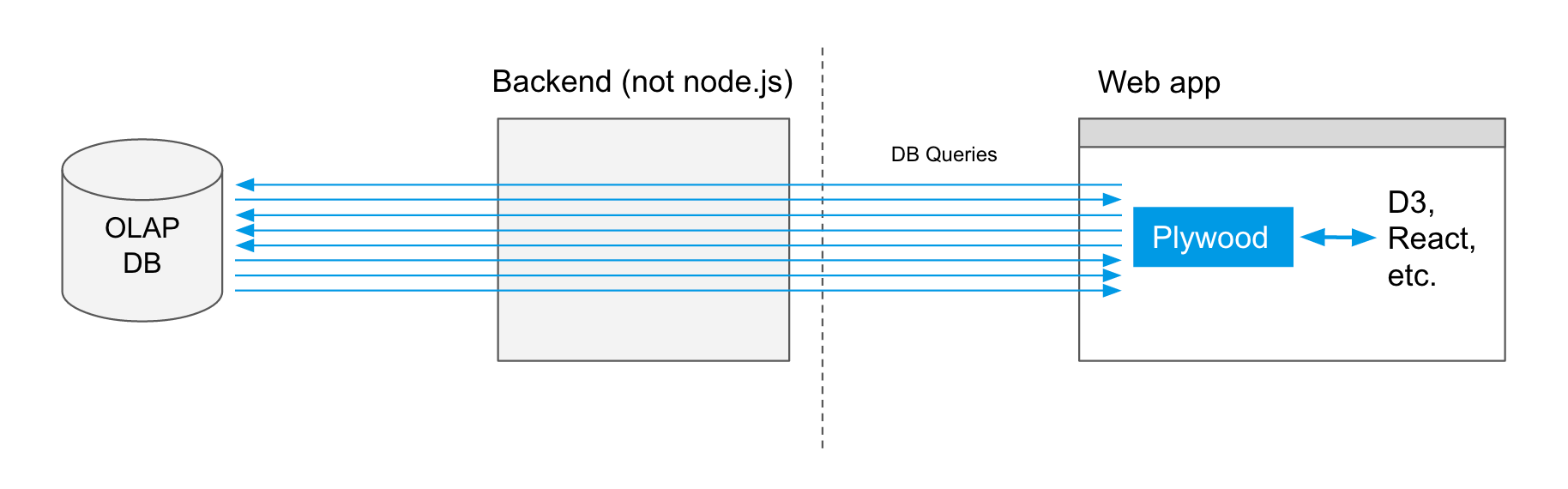
It might be undesirable to have the web app communicate with the DB directly in which case you could also use the plyql in server mode like so:
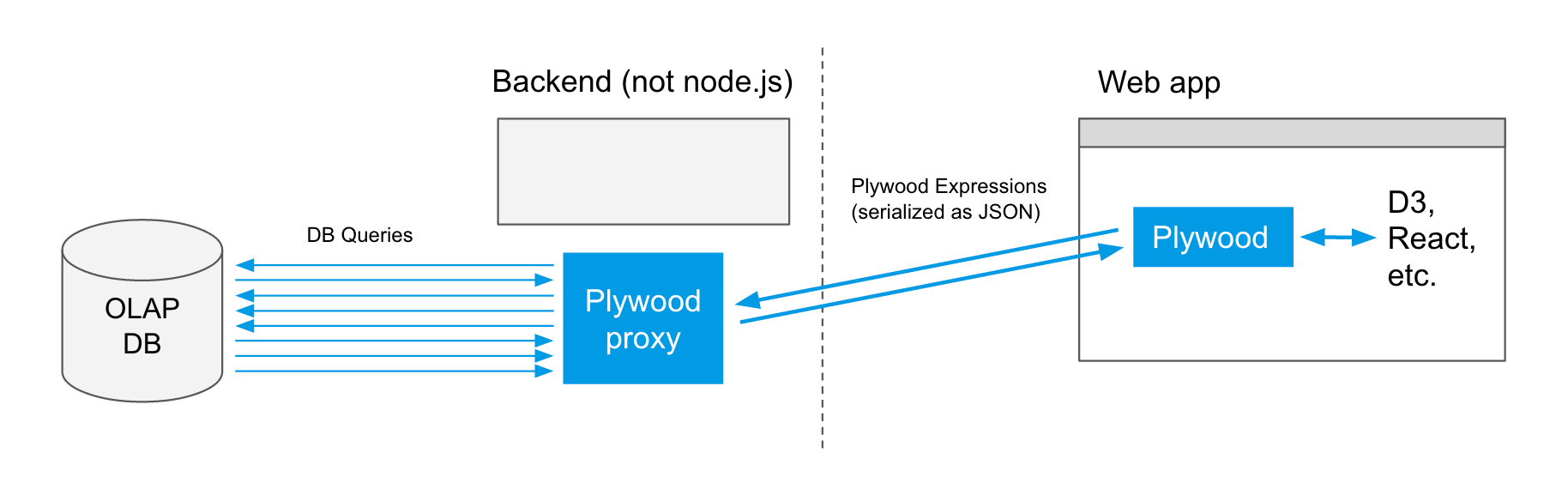
You are building a data-driven application and you are allergic to JavaScript
If JavaScript does not fit into your stack you can still benefit from Plywood by utilizing plyql. Your application could ether generate Plywood queries in their JSON form or as PlyQL SQL strings that it sends over to plyql running in server mode. plyql will send back nested JSON results.
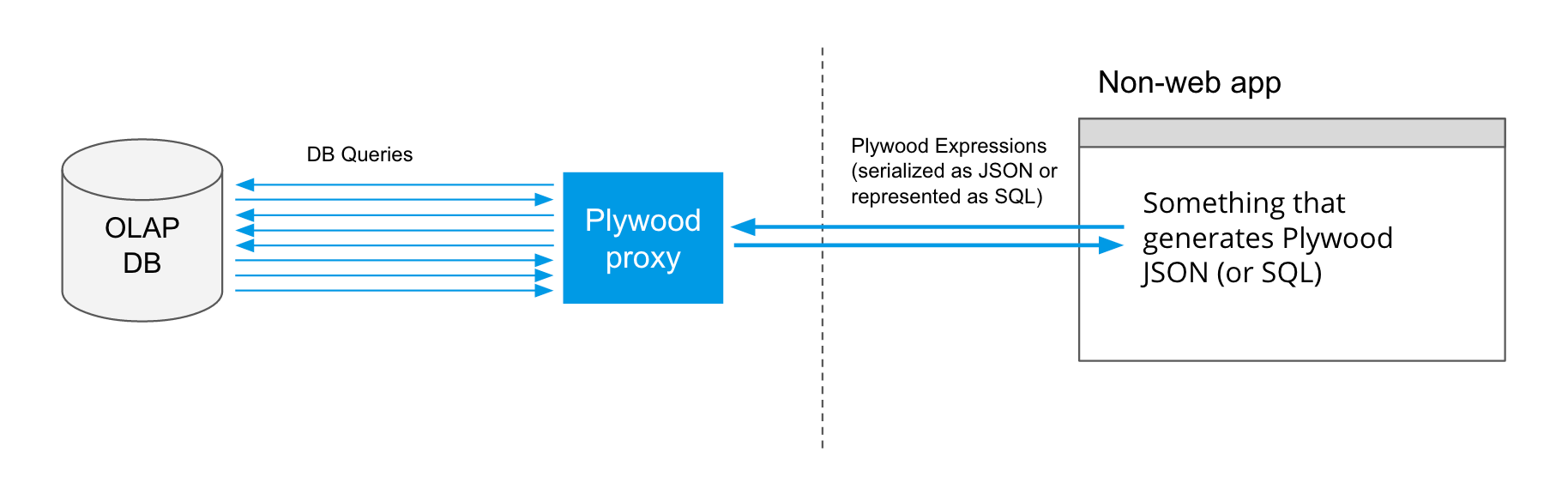
You know SQL and want to query a DB that does not use SQL (like Druid)
Maybe all you want is to have a SQL-like interface to Druid. You can use the plyql command line utility to talk to Druid.

Installation
To use Plywood from npm simply run: npm install plywood.
Plywood can be also used by the browser.
Learn by Example
Example 0
Here is an example of a simple plywood query that illustrates the different ways by which expressions can be created. First of all plywood and its component parts need to be imported into the project. We will import two plywood functions here:
var plywood = require('plywood');
var ply = plywood.ply;
var $ = plywood.$;
ply()creates a dataset with one empty datum inside of it. This is the base of many plywood operations.$()creates a Reference Expression
Now, a simple query can be issued:
var ex0 = ply() // Create an empty singleton dataset literal [{}]
// 1 is converted into a literal
.apply("one", 1)
// The string "$one + 1" is parsed into an expression
.apply("two", "$one + 1")
// The method chaining approach is used to make an expression
.apply("four", $("two").multiply(2))
apply(name, expression)evaluates the givenexpressionfor every element of the dataset and saves the result asname.Calling
ex0.compute()will return a Q promise that will resolve to:
[
{
one: 1
two: 2
four: 4
}
]
Example 1
This example will use Druid as the data store. We will need to import and define some additional components to query external data.
var External = plywood.External;
var druidRequesterFactory = require('plywood-druid-requester').druidRequesterFactory;
- External: An external acts as a query planner and scheduler for its database. More about them here
- DruidRequesterFactory: This is a node specific module. Each external requires a requester function and this module exposes a factory function that makes these requester functions.
Next, the druid connection needs to be configured:
var druidRequester = druidRequesterFactory({
host: '192.168.60.100:8082' // Where ever your Druid may be
});
Construct an external from a JSON definition.
var wikiDataset = External.fromJS({
engine: 'druid',
source: 'wikipedia', // The datasource name in Druid
timeAttribute: 'time', // Druid's anonymous time attribute will be called 'time',
context: {
timeout: 10000 // The Druid context
}
}, druidRequester);
Once that is up and running, we should configure our execution context (Note, this is unrelated to the Druid context defined in the external) The execution context is a map that allows us to define values that our query can refer to. With the following context definition, we can now refer to our wikipedia External as "wiki". Less helpfully, we can also refer to the number 70 with the string "seventy".
var context = {
wiki: wikiDataset,
seventy: 70
};
Now, a simple query can be issued:
var ex = ply()
// Define the external in scope with a filter on time and language
.apply("wiki",
$('wiki').filter($("time").in({
start: new Date("2015-09-12T00:00:00Z"),
end: new Date("2015-09-13T00:00:00Z")
}).and($('channel').is('en')))
)
// Calculate count
.apply('Count', $('wiki').count())
// Calculate the sum of the `added` attribute
.apply('TotalAdded', '$wiki.sum($added)');
// Refer to the seventy defined in the context
.apply('70', $('seventy'));
ex.compute(context).then(function(data) {
// Log the data while converting it to a readable standard
console.log(JSON.stringify(data.toJS(), null, 2));
}).done();
This will output:
[
{
"70": 70,
"TotalAdded": 32553107,
"Count": 113240
}
]
This result is a dataset with a single datum in it.
The attribute of this datum will be the .apply calls that we asked Druid to calculate.
This might not look mind blowing but we can build on this concept.
Example 2
Using the same setup as before we can issue a more interesting query:
var context = {
wiki: wikiDataset
};
var ex = ply()
.apply("wiki",
$('wiki').filter($("time").in({
start: new Date("2015-09-12T00:00:00Z"),
end: new Date("2015-09-13T00:00:00Z")
}))
)
.apply('Count', $('wiki').count())
.apply('TotalAdded', '$wiki.sum($added)')
.apply('Pages',
$('wiki').split('$page', 'Page')
.apply('Count', $('wiki').count())
.sort('$Count', 'descending')
.limit(6)
);
ex.compute(context).then(function(data) {
// Log the data while converting it to a readable standard
console.log(JSON.stringify(data.toJS(), null, 2));
}).done();
Here a sub split is added. The Pages attribute will actually be a dataset that represents the data in wiki
split on the page attribute (labeled as 'Page') and then the top 6 pages will be taken by applying a sort
and limit.
The output will look like so:
[
{
"TotalAdded": 32553107,
"Count": 113240
}
]
[
{
"TotalAdded": 97393743,
"Count": 389319,
"Pages": [
{
"Page": "Jeremy Corbyn",
"Count": 314
},
{
"Page": "User:Cyde/List of candidates for speedy deletion/Subpage",
"Count": 255
},
{
"Page": "Wikipedia:Administrators' noticeboard/Incidents",
"Count": 228
},
{
"Page": "Wikipedia:Vandalismusmeldung",
"Count": 186
},
{
"Page": "Total Drama Presents: The Ridonculous Race",
"Count": 160
},
{
"Page": "Wikipedia:Administrator intervention against vandalism",
"Count": 145
}
]
}
]